This post was written by Jamie Whyte and appears along with other stories about data here.
On thursday, we were contacted by our pals over at ODI Leeds, who have recently held the second in their excellent #TravelHack series.
TfGM (Transport for Greater Manchester) declined the FOI request to make available fares data for 2018. There’s more detail on why this is a bad thing in this post.
We decided that we could probably do something about making current fare data (which is already in the public domain) more accessible, so that people can do stuff with it.
I’ve wanted to do a scraping project for a long time, but never quite fond the right topic, and this seemed ideal. What follows is a semi-instructional guide describing the steps I took to scrape fares data from the TfGM website.
The first thing was to have a look at what’s already there. TfGM have a website that’s currently in beta, but it looks pretty good. There’s a page you can use to check ticket prices. The basic principle is that you choose two Metrolink stations, and the page displays all the different ticket options, with pricing:
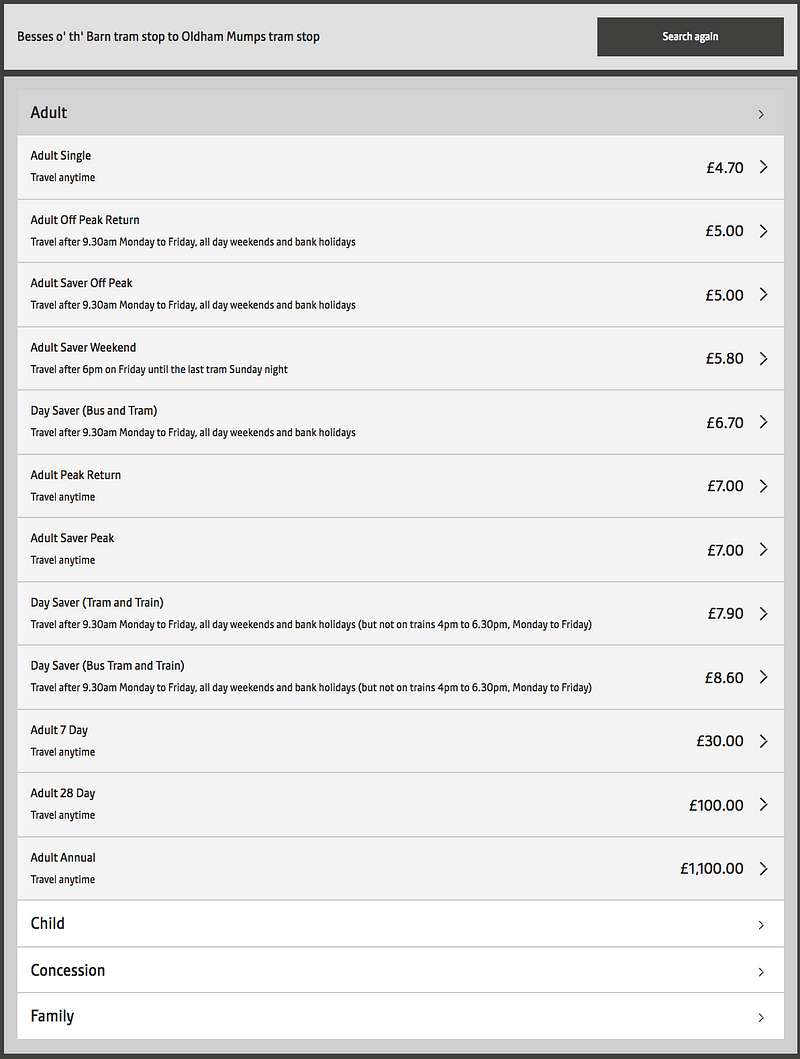
Pretty good, actually. It’s this that we’re going to use as the basis for our project.
Tooled Up
What I wanted to do, then, was somehow get the contents of that page, in some sort of structured format, and then get the same contents for each permutation of stations on the Metrolink system. Python seemed to be the best tool for this job, making use of the BeautifulSoup library. This allows us to extract specific parts of a webpage, and print it, or write it to a file.
Perfecto.
I use PyCharm as my IDE for Python (though in truth, I don’t use python as often as R), and it seems to be pretty good. It checks syntax and errors as you go along, which is useful for inexperienced Pythonistas (Pythoneers?).
Install the BS4 library, using something like this to guide you, and you’re all set. You’ll also need to get the Imports library if you don’t already have it, to allow us to grab things via html.
The basic idea behind Beautiful Soup is that you throw a load of html or xml in, and then you can perform operations on it, using elements of the DOM. The first thing that we need to do, is work out how to tell Beautiful Soup which webpages we want it to parse data from.
Looking back at the TfGM ticket price site — the url is:
https://beta.tfgm.com/public-transport/tram/ticket-prices/besses-o-th-barn-tram/oldham-mumps-tram
See how the url is constructed from a beginning bit, plus the start station, and then the destination station? This is very useful for what we’re going to do, as it means we can procedurally generate the urls of the pages that we want to scrape, as long as we know what the stations are.
So back to the TfGM website, where there is a full list of tram stations. What we need to do is get this list of 93 stops into a list, formatted as needed for the url, and then produce another much bigger list, consisting of every permutation of start / end tram stops on the network. I have to confess, I could probably have scraped this, and then done some string manipulation and then used the itertools library in Python to do this. But I couldn’t work it out. SO I did it in excel.
I copied the full list straight from the webpage into an Excel column, and then:
- Removed the hyperlinks
- Removed the string ‘ stop’
- Removed apostrophes
- Swapped spaces for dashes
I then duplicated this column (ie copied cells A1:A93 into B1:B93), and into column A added a ‘/’ at the end, to help with the url construction. I then found a formula online that created all permutations of those two columns, which I paste into column C, and then dragged down:
=IF(ROW()-ROW($D$1)+1>COUNTA($A$1:$A$4)*COUNTA($B$1:$B$3),””,INDEX($A$1:$A$4,INT((ROW()-ROW($D$1))/COUNTA($B$1:$B$3)+1))&INDEX($B$1:$B$3,MOD(ROW()-ROW($D$1),COUNTA($B$1:$B$3))+1))’
This resulted in 8,649 combinations of stops (93 * 93). I wanted to retain same station to same station for completeness, and it was important to have start stop A /end stop B and start stop B / end stop A in case there are differences in ticket price for each direction. I removed columns A and B, leaving one column of data, and I then saved this as a CSV file into the project folder, called ‘metstopperms.csv’.
Now, for the Python
Now that we have our supporting data prepared, we can get into the Python.
The first thing we need to do is import the appropriate libraries:
from bs4 import BeautifulSoup import requests
Then, we need to get the file that we made with all the permutations of Metrolink stops, which we put into a variable called ‘f’.
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
We then loop through each item from the CSV file, passing it into a variable called ‘stopcombo’:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
And then use that URL to get our data:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
Firstly by constructing the URL that we want to use. What’s happening here is that we’re creating a variable called URL, and loading it with the first part of the URL (which never changes). The curly braces ‘{}’ tell it that that’s a placeholder, and then the .format(stopcombo) appends the variable from the CSV to the end of it. As this is a loop, this happens for each of our stop permutations, one at a time.
We then have to make the call to this URL, using the requests library:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
r = requests.get(url)
Put all the html text from the page into a variable called ‘data’:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
r = requests.get(url)
data = r.text
And then create a BeautifulSoup object with that text:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
r = requests.get(url)
data = r.text
soup = BeautifulSoup(data)
Once this is done, we can now use BeautifulSoup’s functions to extract the bits that we need. Before we do this, though, we need to know what bits we actually need. We can tell BeautifulSoup to pull out any bits from the html that we want. To find out what these are, we need to inspect the html of the page.
In Chrome, open the Developer Tools to see the html of a page.
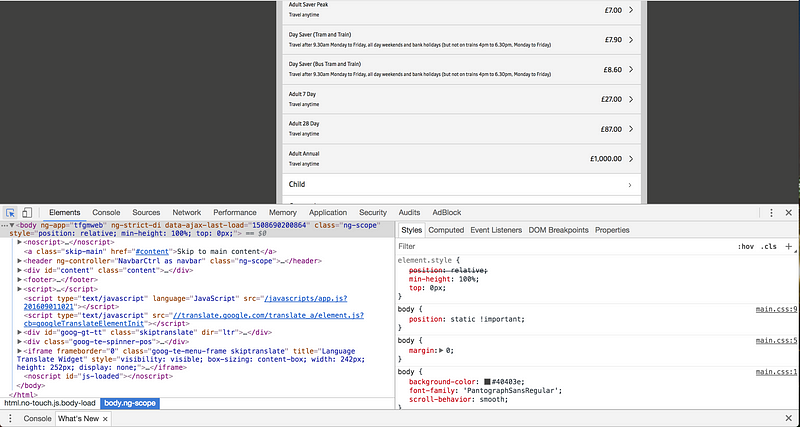
From here, we can explore the how the page has been built. We can click this button in the top left to select individual elements.

If we do that on this page then we can hover over each part of the page, and see how it is represented in the HTML. We want the ticket price and details, so hovering over that shows us that these items live in a set of list items, each of which has the class ‘ticket-info’:
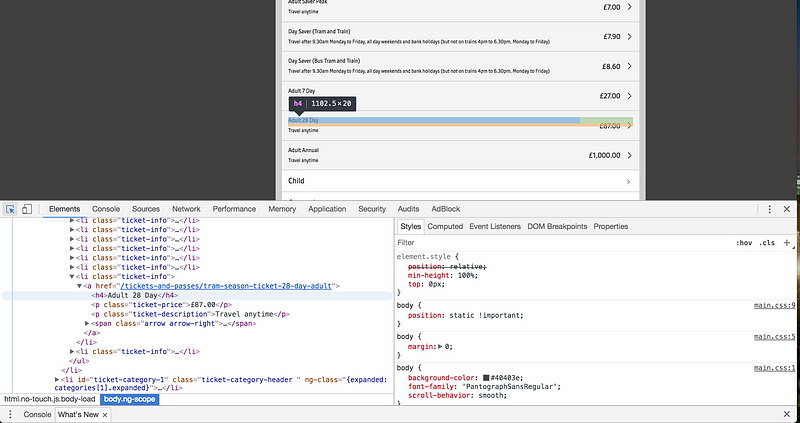
BINGO!
This is what we can use to tell BeautifulSoup what to get for us. So back to the Python, we first need to create a .TXT file to hold the results of this:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
r = requests.get(url)
data = r.text
soup = BeautifulSoup(data)
with open('parseddata.txt', 'a') as t:
So we are saying create a text file called ‘parseddata.txt’ in append mode. Then we want to find each list item (li) in the html with the class ‘ticket-info’, and put it into a thing called ‘price’:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
r = requests.get(url)
data = r.text
soup = BeautifulSoup(data)
with open('parseddata.txt', 'a') as t:
for price in soup.find_all('li', {'class': 'ticket-info'}):
And then write to the file ‘parsedtext.txt’ a concatenated (stuck together) string of the start and end stop (stopcombo), the text from the h4 object inside the list item from the HTML, which corresponds to the ticket type, and the text from the <p> element inside the list item, which corresponds to the price. This text bits are all separated by commas, and then finished off with a newline, to make it easier to use:
from bs4 import BeautifulSoup import requests
with open("metstopperms.csv") as f:
for stopcombo in map(str.f):
url = 'https://beta.tfgm.com/public-transport/tram/ticket-prices/{}'.format(stopcombo)
r = requests.get(url)
data = r.text
soup = BeautifulSoup(data)
with open('parseddata.txt', 'a') as t:
for price in soup.find_all('li', {'class': 'ticket-info'}):
t.write(str(stopcombo) + ',' + str(price.h4.text) + ',' + str(price.p.text) + '\n')
And that’s the entire bock of code. Two loops — one that loops through all pages, and one that loops through the list items on a page.
This generated a text file with 222,000 lines of information, and took 42 minutes. I suspect that I could have optimised this in some way, but for my first attempt at scraping, overall, I’m calling this a success.
Everything here is in a GitHub repo — please do feel free to use it, pull it apart, make fun of me, and use it for your own scraping projects. On the face of it, scraping is a pretty daunting task, but it’s actually quite straightforward..!